





赛道 | 深兰科技折桂 2021SemEval,双赛道比拼中获得“两冠一亚”
2021-08-01SemEval是由国际计算语言学协会(Association for Computational Linguistics,ACL)主办的国际语义评测大赛, SemEval是全球范围内影响力最强、规模最大、参赛人数最多的语义评测竞赛。自2001年起,SemEval已成功举办十五届,吸引了卡内基梅隆大学、哈工大、中科院、微软和百度等国内外一流高校、顶级科研机构和知名企业参与。
8 月 1 日- 6 日,SemEval2021与ACL-IJCNLP 2021 在泰国曼谷共同举办。深兰科技作为人工智能头部企业,参加了“词汇复杂度预测(任务一)”和“幽默性和冒犯性文本识别与评估(任务七)”两个大任务中的6个子任务,最终获得2项第一、1项第二、1项第三,共计4项top3。团队在赛事中运用的相关技术和模型已成功应用于公司的自动化机器学习平台中。
赛事介绍
任务一Lexical Complexity Prediction (LCP)
任务一为上下文中词汇的复杂度预测任务,任务分为两个子任务,子任务1为预测单个单词的复杂度,子任务2为预测词组(多词表达)的复杂度。其中数据样例如下:
Table 1 数据样例
结合数据可以看出当前任务为一个回归任务,即基于上下文预测给定词汇的复杂度,深兰团队在两个子任务的排名如下,团队在子任务1获得了第二名,在子任务2中获得了第一名。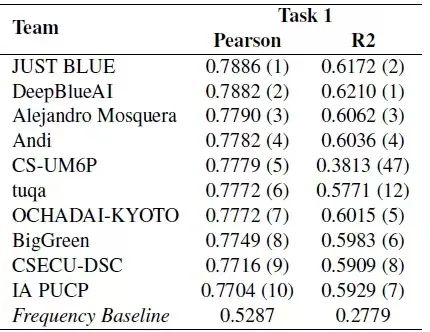
子任务1 成绩排名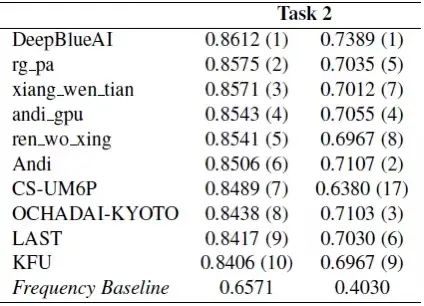
子任务2 成绩排名
任务七HaHackathon: Detecting and Rating Humor and Offense
任务七为幽默性和冒犯性文本识别与评估任务,也是首次将幽默性和冒犯性识别结合起来的任务,因为文本对一些用户来说是幽默的,但是对其他用户来说可能是冒犯的,举办方共将任务划分为幽默性识别和冒犯性识别,其中幽默性识别又被划分为三个子任务,共计4个子任务,分别为:
子任务1a:预测文本是否会被视为幽默,为二分类任务;
子任务1b:如果文本被归类为幽默,预测它的幽默程度,为回归任务;
子任务1c:如果文本被归类为幽默,预测当前幽默评级是否有争议,二分类任务;
子任务2a:预测文本的冒犯程度,为回归任务
深兰团队同时参加了4个任务,其中在任务1a、1c、2a取得了较好的成绩,在子任务2a中获得了第一名,在子任务1a中获得了第三名,在子任务1c中获得了第五名。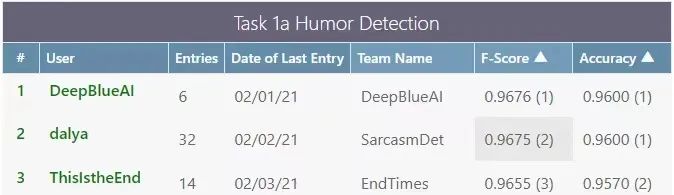
Task 1a 
Task 2a
方案
上述几个任务都是标准的分类任务或者回归任务,深兰团队采取了统一的模型和训练方案,半自动化的完成模型的训练和融合。模型采用当前主流的预训练模型,如BERT,基于预训练模型构建分类和回归模型,模型图如下:
模型图
模型主要分为以下几个部分,文本输入、CLS向量加权平均、全连接、Multi-sample dropout:
文本输入针对句子级别分类或者回归模型,一般为单个句子输入或者两个句子。例如对于上述Task7为单个句子输入,而对于Task1则需要变成两个句子输入,句子一为待识别的词,句子二为上下文文本。
BERT有两个特殊的标示符,分别是[CLS]、[SEP],其中[CLS]在训练的时候,用在Next Sentence Prediction任务上,[CLS]可以代表整个句子的语义表示,[CLS]通常用在句子级别的分类任务上。当前任务也是句子级别的分类任务,深兰团队的模型也是采取[CLS]位置的向量进行分类。为了提取更深层次的语义特征,深兰团队不仅仅用BERT最后一层的输出,而是选取多层[CLS]位置向量进行加权平均,来代表整个句子的语义表示。
Multi-sample dropout 是dropout的一种变种,传统 dropout 在每轮训练时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后平均所有样本的损失,从而得到最终的损失,multi-sample dropout 共享中间的全连接层权重。通过综合 M个dropout 样本的损失来更新网络参数,使得最终损失比任何一个 dropout 样本的损失都低。这样做的效果类似于对一个minibatch中的每个输入重复训练 M 次。因此,它大大减少训练迭代次数,从而大幅加快训练速度。由于大部分运算发生在 dropout 层之前的BERT层中,Multi-sample dropout 并不会重复这些计算,对每次迭代的计算成本影响不大。实验表明,multi-sample dropout 还可以降低训练集和验证集的错误率和损失。
损失函数,当前模型可以适用于分类和回归任务,只需改变损失函数即可,对于分类任务主要采用的损失函数为Cross Entropy 、Binary Cross Entropy、focal loss等,对于回归任务主要采用的损失函数为均方误差(Mean Square Error, MSE)、平均绝对误差(Mean Absolute Error, MAE)等。
方案流程解读
基于上述模型,深兰的方案流程为:
1、选择合适的预训练模型,首先基于构建好的baseline选取多种预训练模型进行测试,如BERT、RoBERTa、ALBERT、ERNIE等,之后选取最好的或者几个比较好的预训练模型。
2、领域自适应预训练(DAPT),利用在所属的领域数据上继续预训练,例如针对Task1,数据主要来源为医疗、圣经、欧洲议会记录,则选择这几个领域的数据继续进行掩码语言模型任务(MLM),提升预训练模型在当前领域上的性能。
3、任务自适应预训练(TAPT),在当前和任务相关的数据集上进行掩码语言模型(MLM)训练提升预训练模型在当前数据集上的性能。
4、对抗训练,对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,从而提升模型的鲁棒性和泛化能力。深兰团队采用FGM(Fast Gradient Method),通过在嵌入层加入扰动,从而获得更稳定的单词表示形式和更通用的模型,以此提升模型效果。
5、伪标签,将测试集打上标签,并加入到训练集中,增大训练集的数量,提升最后的效果。
6、知识蒸馏,知识蒸馏由Hinton在2015年提出,主要应用在模型压缩上,通过知识蒸馏将大模型所学习到的有用信息来训练小模型,在保证性能差不多的情况下进行模型压缩。深兰团队将利用模型压缩的思想,采用模型融合的方案,融合多个不同的模型作为teacher模型,将要训练的作为student模型。
7、模型融合,为了更好地利用数据,深兰团队采用7折交叉验证,针对每个会使用了多种预训练模型,又通过改变不同的参数随机数种子以及不同的训练策略训练了多个模型。最后采用线性回归、逻辑回归等机器学习模型进行融合。
总 结
利用上述构建的框架,深兰团队参加了任务一和任务7共计6个子任务,获得了4项奖项,充分证明了方案的可行性,并且当前方案相关技术以及模型成功应用于公司的自动化机器学习平台中,深兰自动化机器学习平台以低门槛、广覆盖、高精度、少成本的优势,为各个行业领域提供核心算法。
-

8项冠亚季军收官ECCV2020,深兰获三大视觉顶会挑战赛大满贯
计算机视觉 -

与腾讯、哈工大同台竞技,深兰获自然语言处理领域国际顶会NAACL2021冠军
计算机视觉 -

捷报 | 深兰科技“双队”出征CVPR2021 斩获五冠共获14项大奖
计算机视觉 -

2022CVPR传捷报丨深兰科技再度折桂,连续4届获得CVPR挑战赛冠军
计算机视觉 -

深兰科技夺冠CCKS2022“带条件的分层级多答案问答”评测任务竞赛
自然语言处理 -

PK 656 个对手!深兰科技在全球顶级AI赛事kaggle竞赛中再次夺冠
计算机视觉 -

一冠三亚二季!深兰科技在EMNLP2022国际顶级赛事再创佳绩
数据挖掘 -

6个奖项!深兰科技在CVPR 2023挑战赛中再获佳绩
计算机视觉 -

6冠3亚2季!深兰科技在RANLP2023国际赛事上斩获11项大奖
计算机视觉